


DNA and RNA
DNA and RNA have a double helix structure. Phosphate groups make up the backbone (in grey), while the middle of the double helix is formed by pairs of nitrogenous bases (colored pieces). Each type of nitrogenous base pairs with another specific base. Cytosine pairs with Guanine, while Adenine pairs with Thymine in DNA, and vice versa. When we talk about RNA (one side of the helix) then Adenine pairs with Uracil. This is why, depending on the notation you read, you may find T (for Thymine) and U (for Uracil). For the sake of simplicity in the explanation below, we will only use the DNA notation. DNA is like a long thread made of “base pairs” A-T and G-C only Genes contain the information to make proteins.

RNA composition
In order for DNA to make proteins, it must be transcribed by messenger RNA (mRNA). The mRNA “reads” the DNA three bases at a time, matching its complementary bases to it. These groups of three bases are called codons, and each codon codes for a different amino acid. Chains of amino acids make up proteins.
One set of three bases means “start”, others specify the 20 different
amino acids (gene building blocks) and some combination means “stop”
The complete list of all bases is called genome
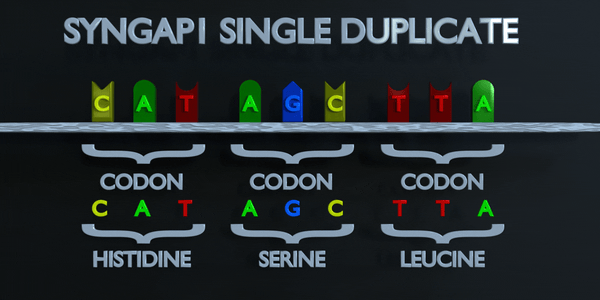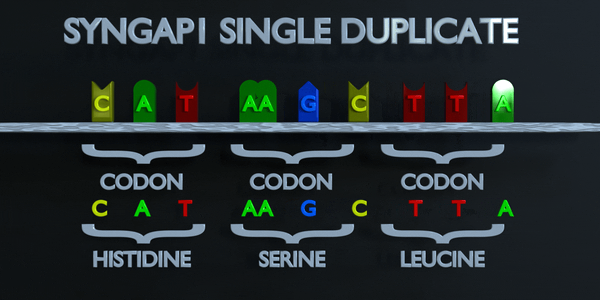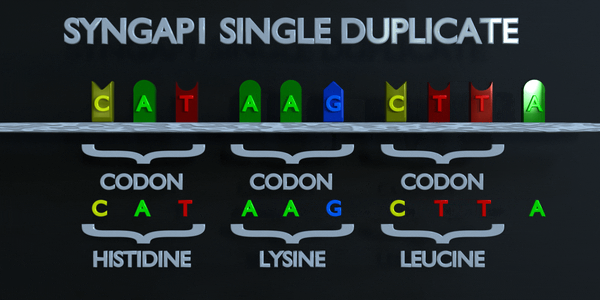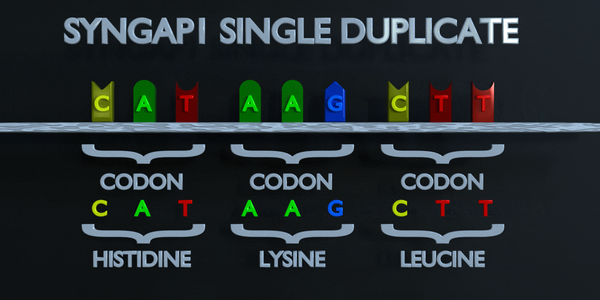
Duplication
As with all mutations, a duplication mutation can drastically change the proteins created by an organism. The proteins responsible for reading DNA process the molecule in units of three base pairs at a time. These codons each specify a different amino acid. If the sequence change even by one nucleotide, a different amino acid is placed within the protein. The function of each protein is dependent on the specific interaction between the amino acids they consist of. A duplicationmutation can displace many more than one nucleotide. In this case, it may make the protein completely dysfunctional, or give it an entirely new function. New adaptations can arise this way, if they are transferred to the offspring and are beneficial. However, the large majority of mutations are deleterious, or cause negative effects.
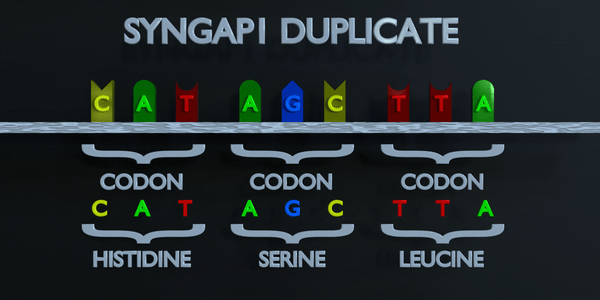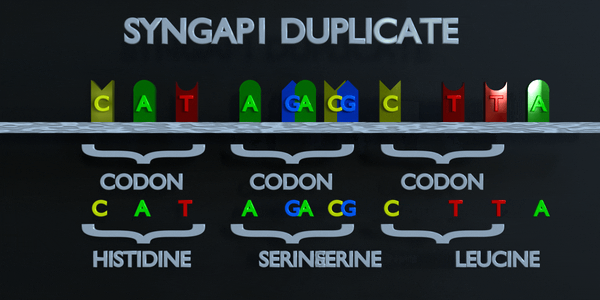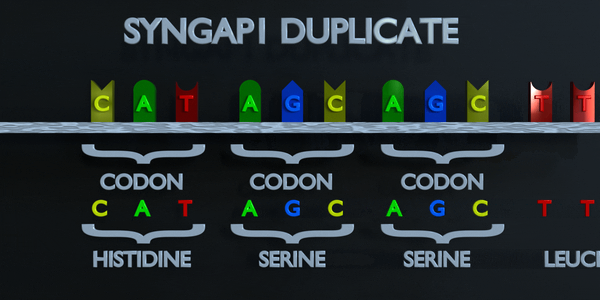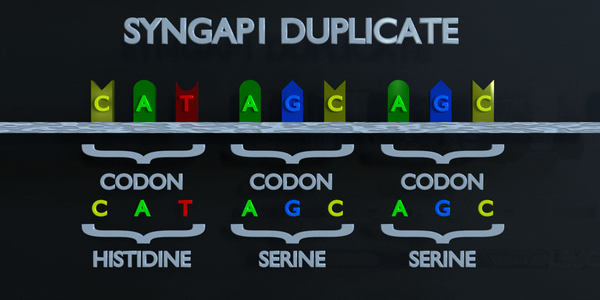
Full Codon Duplication
As with all mutations, a duplication mutation can drastically change the proteins created by an organism. The proteins responsible for reading DNA process the molecule in units of three base pairs at a time. These codons each specify a different amino acid. If the sequence change even by one nucleotide, a different amino acid is placed within the protein. The function of each protein is dependent on the specific interaction between the amino acids they consist of. A duplication mutation can displace many more than one nucleotide. In this case, it may make the protein completely dysfunctional, or give it an entirely new function. New adaptations can arise this way, if they are transferred to the offspring and are beneficial. However, the large majority of mutations are deleterious, or cause negative effects.
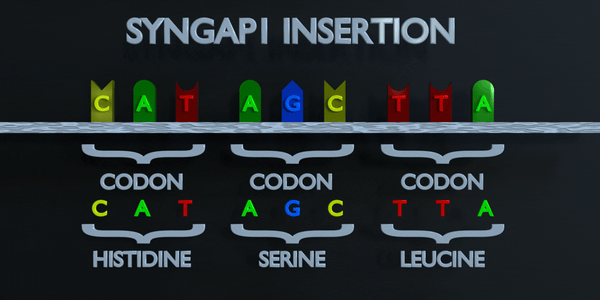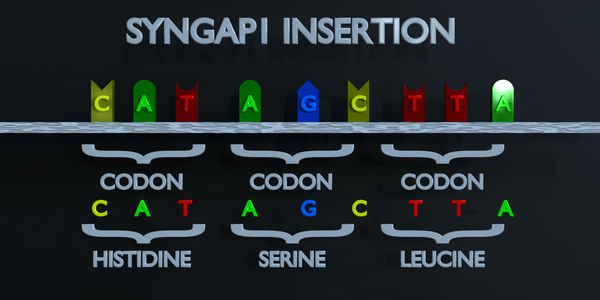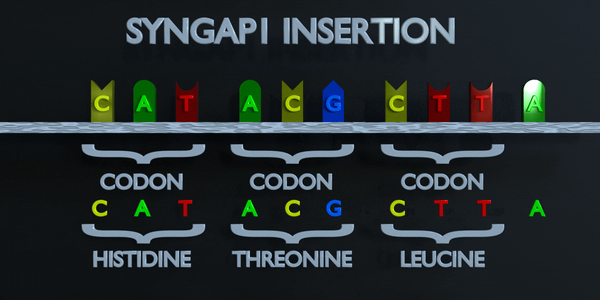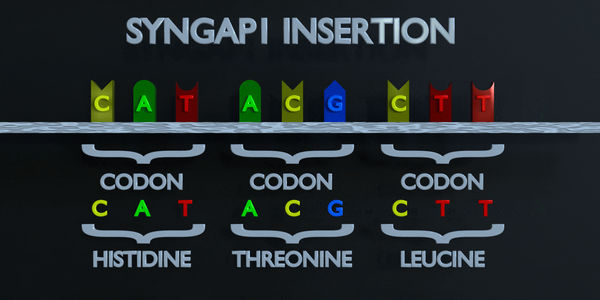
Insertion
Insertions and deletions refer to the addition or removal of short stretches of nucleotide sequences. These types of mutations are usually more deleterious than substitutions since they can cause frame shift mutations, altering the entire amino acid sequence downstream of the mutation site.
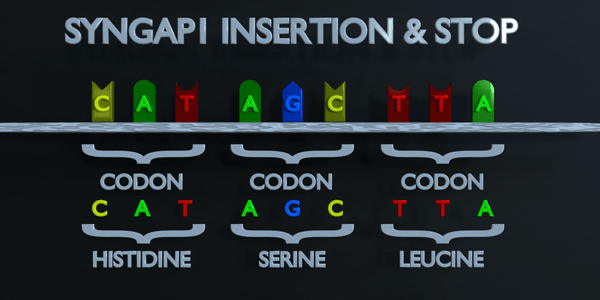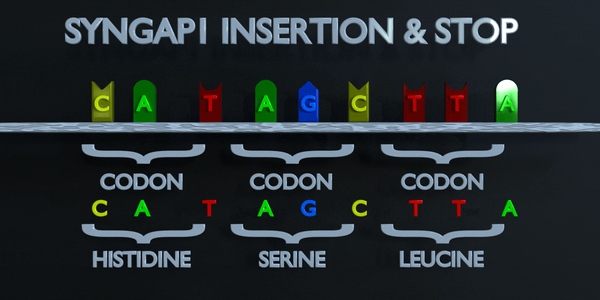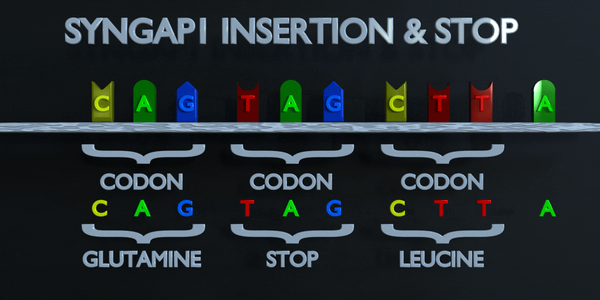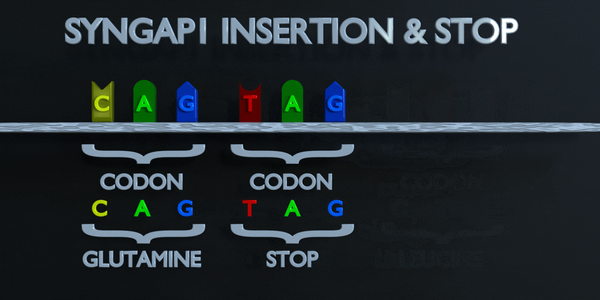
Insertion and Stop (Frameshift)
The genetic code is read in triplets by protein producing enzymes. If three or more nucleotides are added in a gene, entire amino acids can be missing from protein created which can have serious functional effect. Adding a single nucleotide is often not better, as a frameshift mutation can occur. A frameshift mutation shifts the entire gene, and changes all of the original triplet codons. A mutation of this type can cause a gene to produce a completely non-functional gene, as it seriously alters the chain of amino acids the gene produces.
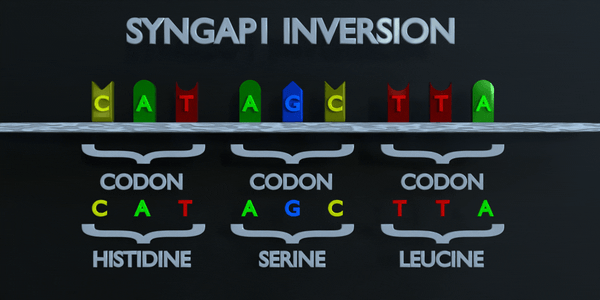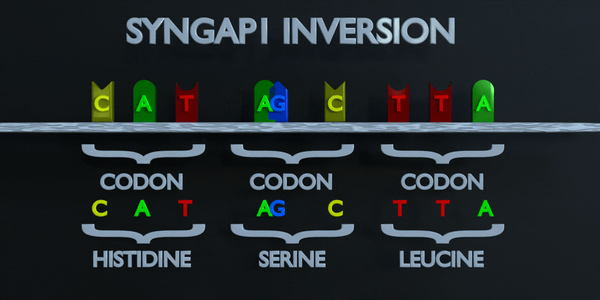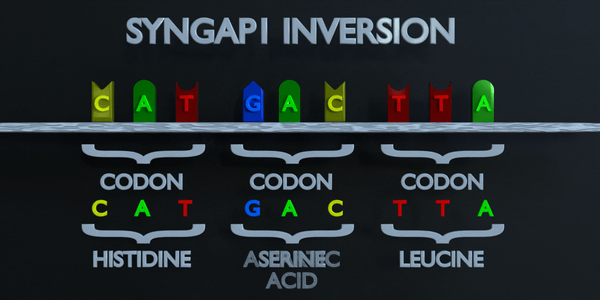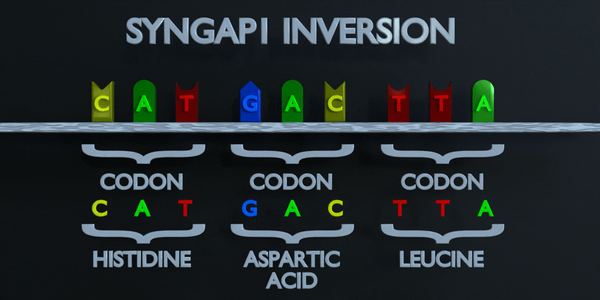
Inversion
Inversion refer to the switching of nucleotide sequences.
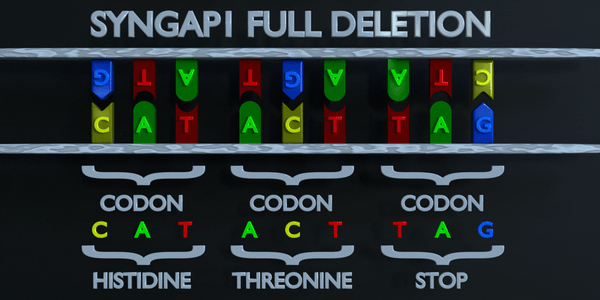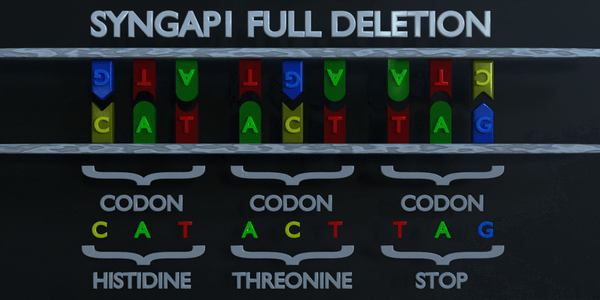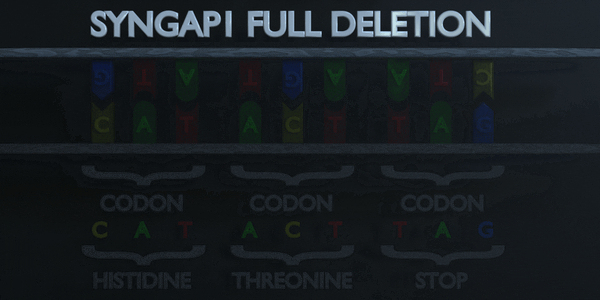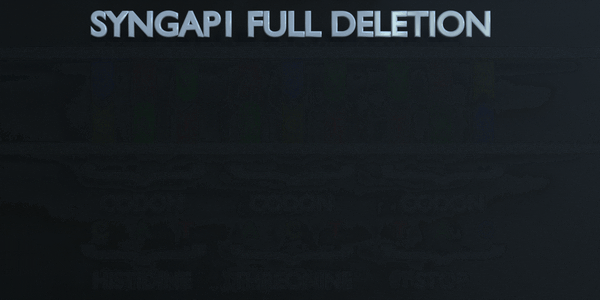
Full Gene Deletion
Sometime, the full gene can be missing (entirely deleted).

Nonsense/Substitution
A nonsense mutation occurs when one nucleotide is substituted and this leads to the formation of a stop codon instead of a codon that codes for an amino acid. A stop codon a certain sequence of bases (TAG, TAA, or TGA in DNA,) that stops the production of the amino acid chain. It is always found at the end of the mRNA sequence when a protein is being produced, but if a substitution causes it to appear in another place, it will prematurely terminate the amino acid sequence and prevent the correct protein from being produced.

Missense
Like a nonsense mutation, a missense mutation occurs when one nucleotide is substituted and a different codon is formed; but this time, the codon that forms is not a stop codon. Instead, the codon produces a different amino acid in the sequence of amino acids. For example, if a missense substitution changes a codon from AGC to GGC, the amino acid Glycine will be produced instead of Serine. A missense mutation is considered conservative if the amino acid formed via the mutation has similar properties to the one that was supposed to be formed instead. It is called non-conservative if the amino acid has different properties that structure and function of a protein.
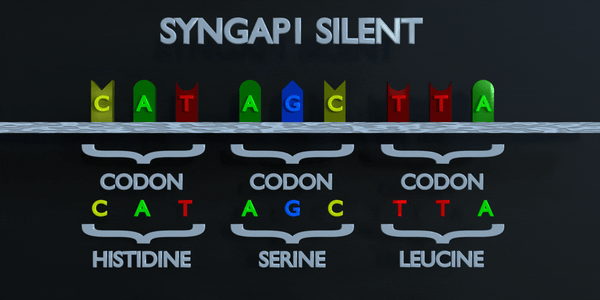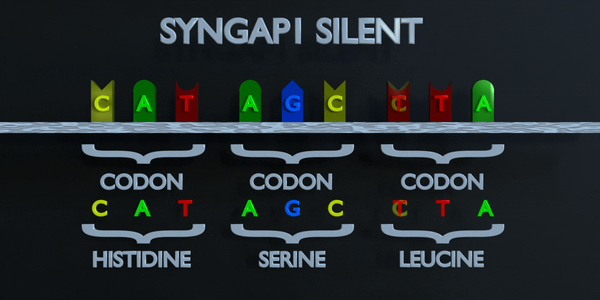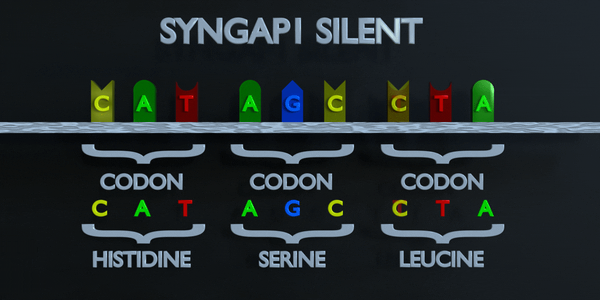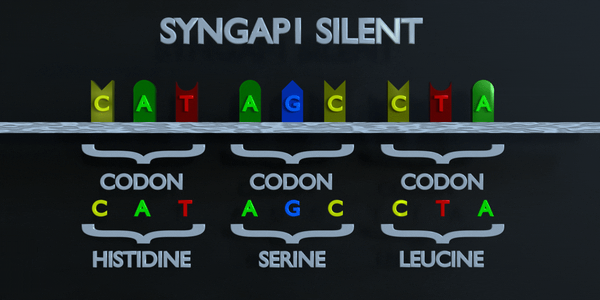
Silent
In a silent mutation, a nucleotide is substituted but the same amino acid is produced anyway. This can occur because multiple codons can code for the same amino acid. For example, TTA and CTA both code for Leucine, so if the first T is changed to a C, the same amino acid will form and the protein will not be affected.
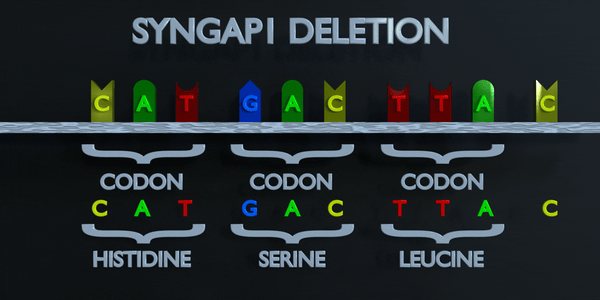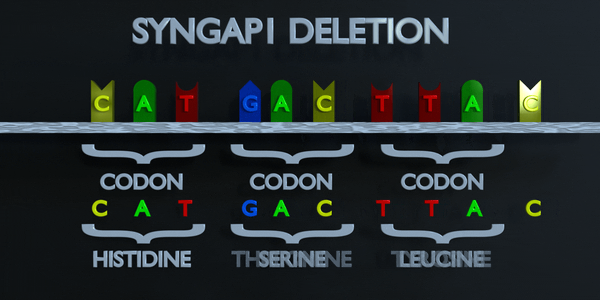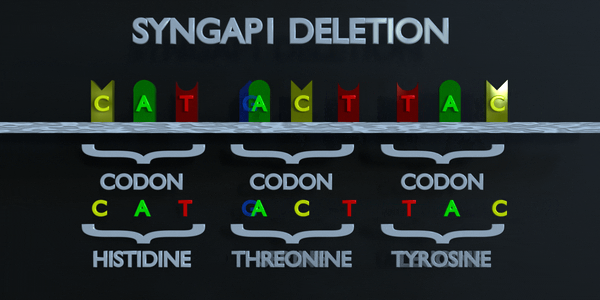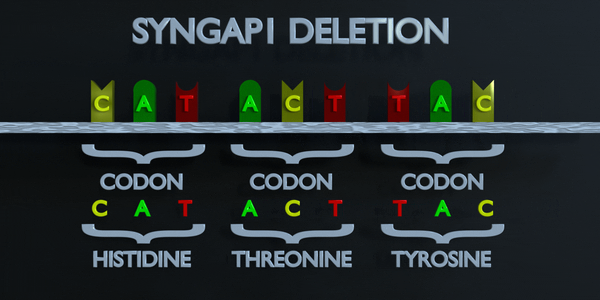
Deletion
A deletion mutation is a mistake in the DNA replication process which removes nucleotides from the genome. A deletion mutation can remove a single nucleotide, or entire sequences of nucleotides. The effect of the deletion mutation will be determined by where in the gene it takes place, and how many nucleotides are deleted. The genetic code is read in triplets by protein producing enzymes. If three or more nucleotides are lost in a gene, entire amino acids can be missing from protein created which can have serious functional effect. Losing a single nucleotide is often not better, as a frameshift mutation can occur. A frameshift mutation shifts the entire gene, and changes all of the original triplet codons. A mutation of this type can cause a gene to produce a completely non-functional gene, as it seriously alters the chain of amino acids the gene produces.