


ADN et ARN
L'ADN et l'ARN ont une structure en double hélice. Les groupements phosphates constituent le squelette (en gris), tandis que le milieu de la double hélice est formé par des paires de bases azotées (morceaux colorés). Chaque type de base azotée s'apparie avec une autre base spécifique. La cytosine s'apparie avec la guanine, tandis que l'adénine s'apparie avec la thymine dans l'ADN, et vice versa. Lorsque nous parlons d'ARN (un côté de l'hélice), l'adénine s'apparie avec l'uracile. C'est pourquoi, selon la notation que vous lisez, vous pouvez trouver T (pour Thymine) et U (pour Uracile). Par souci de simplicité dans l'explication ci-dessous, nous n'utiliserons que la notation ADN. L'ADN est comme un long fil fait de "paires de bases" AT et GC uniquement. Les gènes contiennent les informations nécessaires à la fabrication des protéines.

Composition de l'ARN
Pour que l'ADN fabrique des protéines, il doit être transcrit par l'ARN messager (ARNm). L'ARNm "lit" l'ADN trois bases à la fois, en y faisant correspondre ses bases complémentaires. Ces groupes de trois bases sont appelés codons, et chaque codon code pour un acide aminé différent. Les chaînes d'acides aminés constituent les protéines. Un ensemble de trois bases signifie "démarrer", d'autres spécifient les 20 acides aminés différents (blocs de construction des gènes) et une combinaison signifie "arrêter" La liste complète de toutes les bases est appelée génome
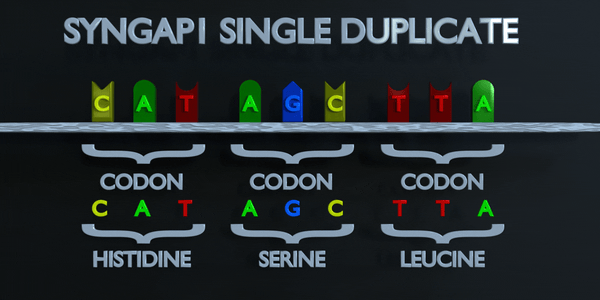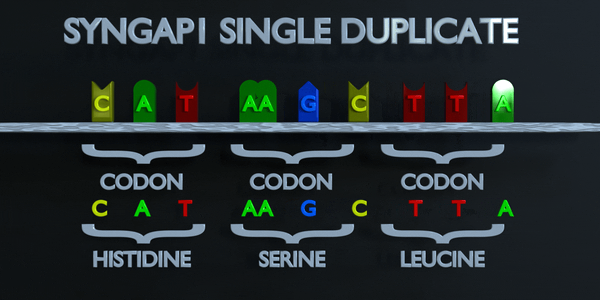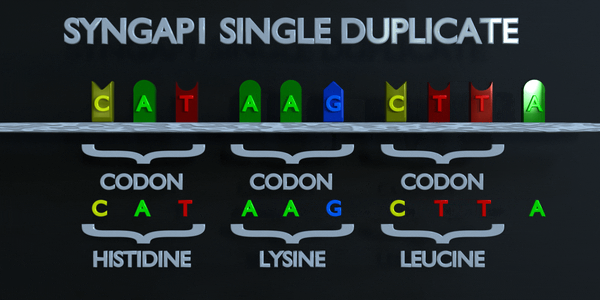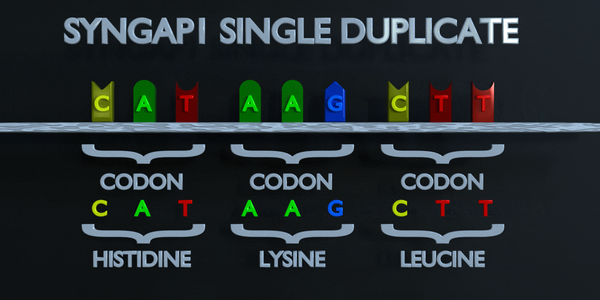
Duplication
Comme pour toutes les mutations, une mutation de duplication peut modifier radicalement les protéines créées par un organisme. Les protéines responsables de la lecture de l'ADN traitent la molécule en unités de trois paires de bases à la fois. Ces codons spécifient chacun un acide aminé différent. Si la séquence change ne serait-ce que d'un nucléotide, un acide aminé différent est placé dans la protéine. La fonction de chaque protéine dépend de l'interaction spécifique entre les acides aminés qui la composent. Une mutation de duplication peut déplacer plusieurs nucléotides. Dans ce cas, cela peut rendre la protéine complètement dysfonctionnelle ou lui donner une fonction entièrement nouvelle. De nouvelles adaptations peuvent survenir de cette façon, si elles sont transférées à la progéniture et sont bénéfiques. Cependant, la grande majorité des mutations sont délétères ou provoquent des effets négatifs.
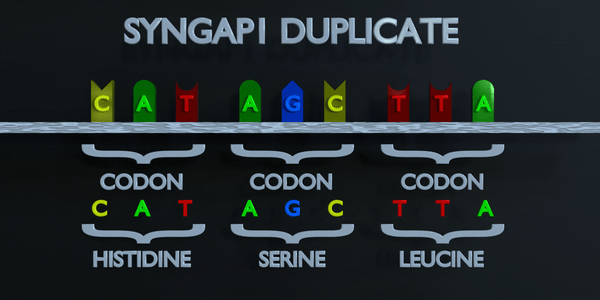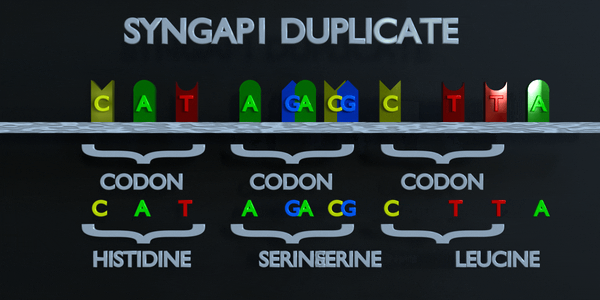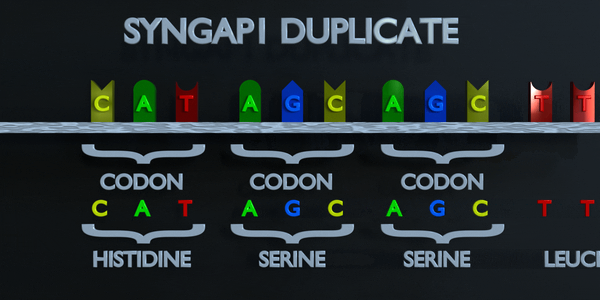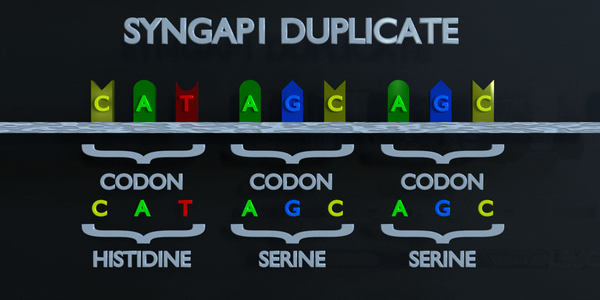
Duplication complète des codons
Comme pour toutes les mutations, une mutation de duplication peut modifier radicalement les protéines créées par un organisme. Les protéines responsables de la lecture de l'ADN traitent la molécule en unités de trois paires de bases à la fois. Ces codons spécifient chacun un acide aminé différent. Si la séquence change ne serait-ce que d'un nucléotide, un acide aminé différent est placé dans la protéine. La fonction de chaque protéine dépend de l'interaction spécifique entre les acides aminés qui la composent. Une mutation de duplication peut déplacer plusieurs nucléotides. Dans ce cas, cela peut rendre la protéine complètement dysfonctionnelle ou lui donner une fonction entièrement nouvelle. De nouvelles adaptations peuvent survenir de cette façon, si elles sont transférées à la progéniture et sont bénéfiques. Cependant, la grande majorité des mutations sont délétères ou provoquent des effets négatifs.
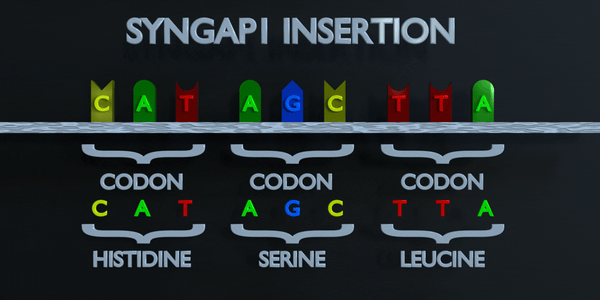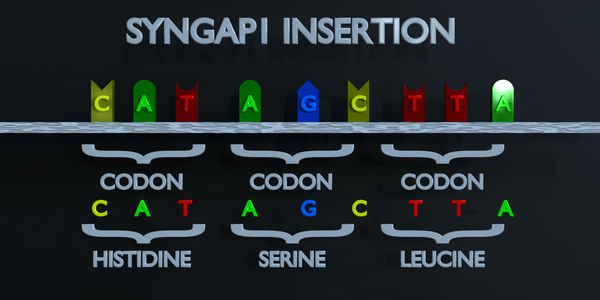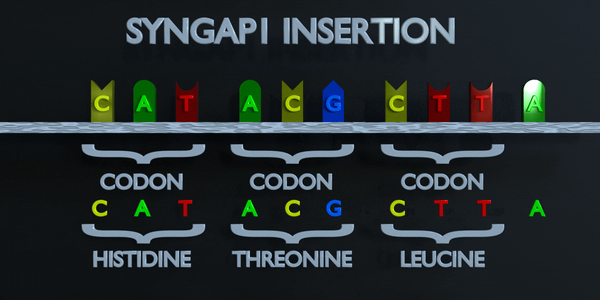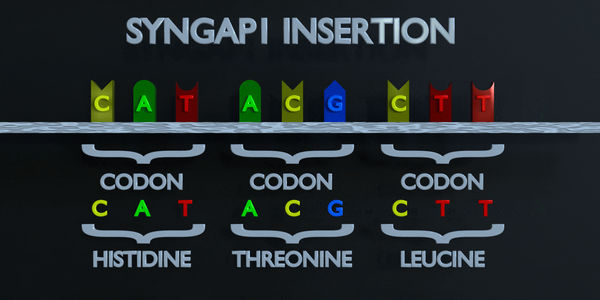
Insertion
Les insertions et les délétions font référence à l'ajout ou à la suppression de courtes séquences de séquences nucléotidiques. Ces types de mutations sont généralement plus délétères que les substitutions car elles peuvent provoquer des mutations par décalage de cadre, altérant toute la séquence d'acides aminés en aval du site de mutation.
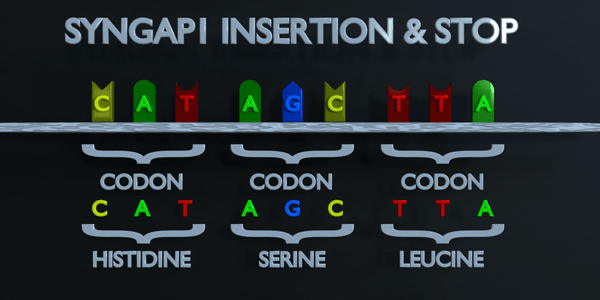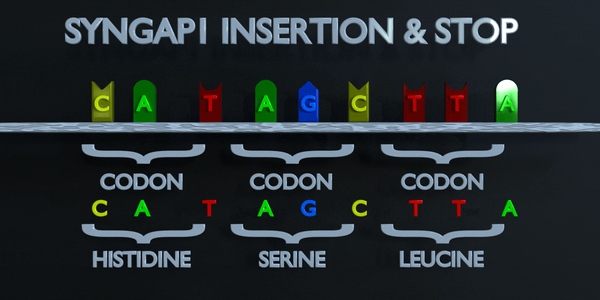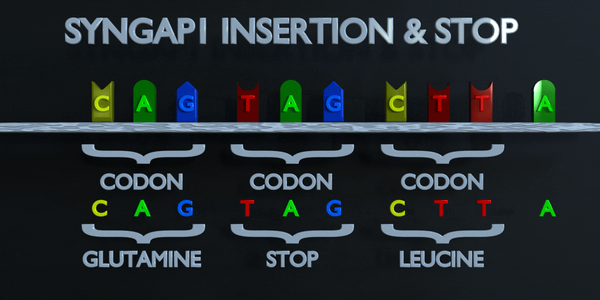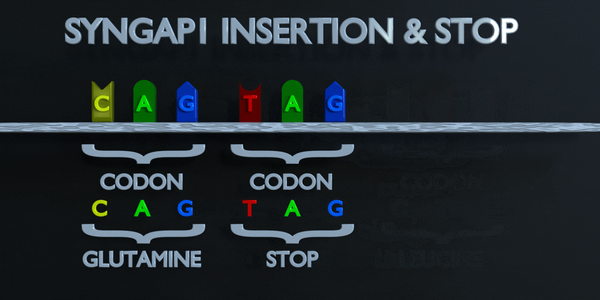
Insertion et Arrêt (Frameshift)
Le code génétique est lu en triplets par des enzymes productrices de protéines. Si trois nucléotides ou plus sont ajoutés dans un gène, des acides aminés entiers peuvent être absents de la protéine créée, ce qui peut avoir de graves effets fonctionnels. L'ajout d'un seul nucléotide n'est souvent pas préférable, car une mutation par décalage de cadre peut se produire. Une mutation de décalage de cadre déplace le gène entier et modifie tous les codons triplets d'origine. Une mutation de ce type peut amener un gène à produire un gène complètement non fonctionnel, car elle altère sérieusement la chaîne d'acides aminés que le gène produit.
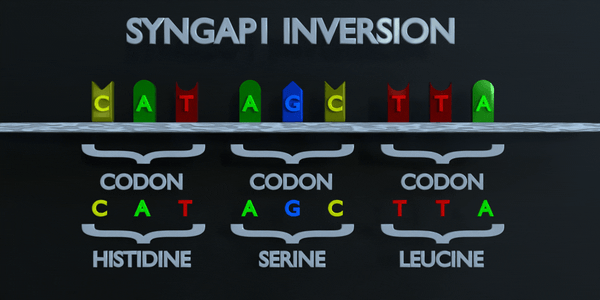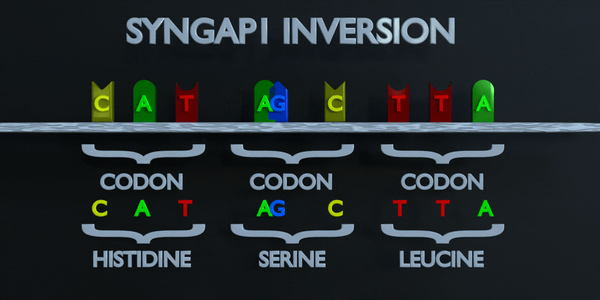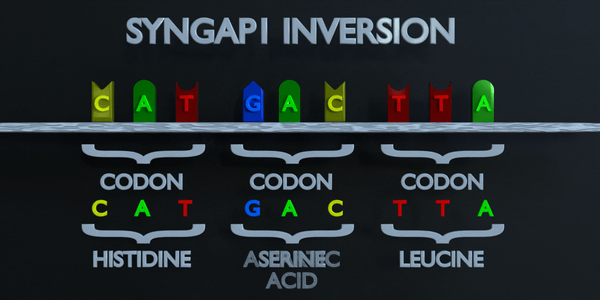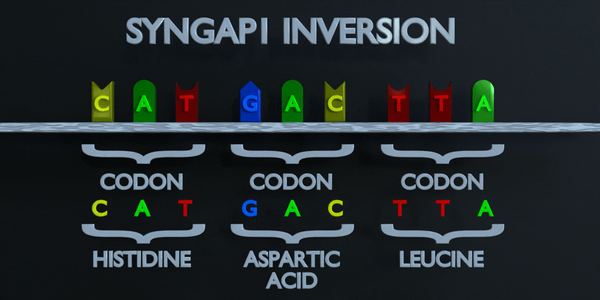
Inversion
L'inversion fait référence à la commutation de séquences nucléotidiques.
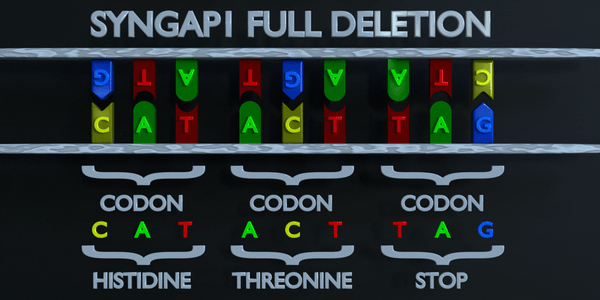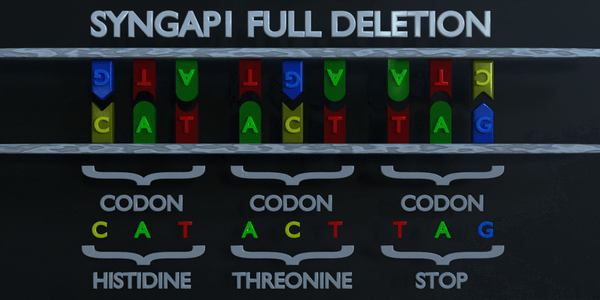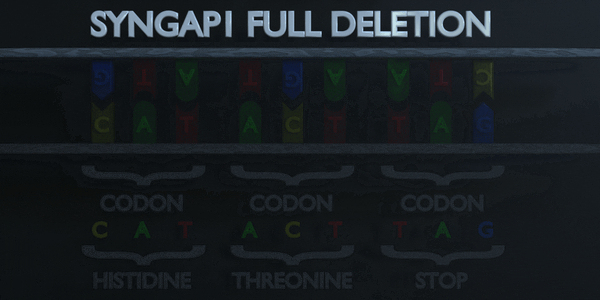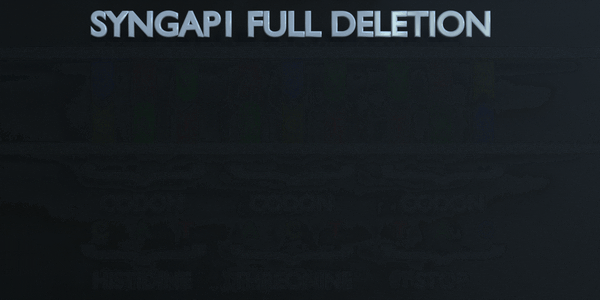
Suppression complète du gène
Parfois, le gène complet peut être manquant (entièrement supprimé).

Non-sens/substitution
Une mutation non-sens se produit lorsqu'un nucléotide est substitué et cela conduit à la formation d'un codon stop au lieu d'un codon qui code pour un acide aminé. Un codon stop une certaine séquence de bases (TAG, TAA ou TGA dans l'ADN) qui arrête la production de la chaîne d'acides aminés. Il se trouve toujours à la fin de la séquence d'ARNm lors de la production d'une protéine, mais si une substitution le fait apparaître à un autre endroit, il terminera prématurément la séquence d'acides aminés et empêchera la bonne protéine d'être produite.

Faux-sens/substitution
Comme une mutation non-sens, une mutation faux-sens se produit lorsqu'un nucléotide est remplacé et qu'un codon différent est formé; mais cette fois, le codon qui se forme n'est pas un codon stop. Au lieu de cela, le codon produit un acide aminé différent dans la séquence d'acides aminés. Par exemple, si une substitution faux-sens change un codon d'AGC en GGC, l'acide aminé Glycine sera produit à la place de la Sérine. Une mutation faux-sens est considérée comme conservatrice si l'acide aminé formé via la mutation a des propriétés similaires à celui qui était censé être formé à la place. Il est dit non conservateur si l'acide aminé a des propriétés différentes de la structure et de la fonction d'une protéine.
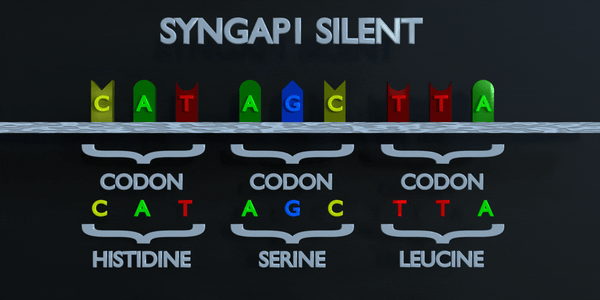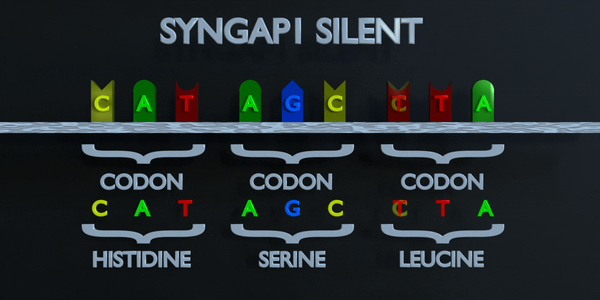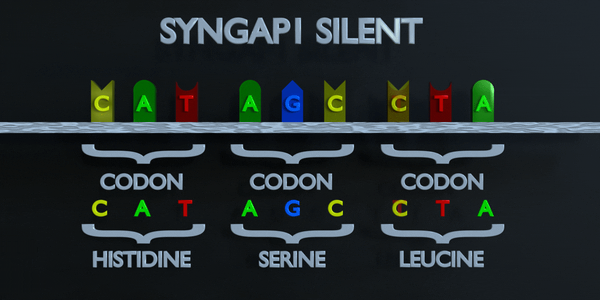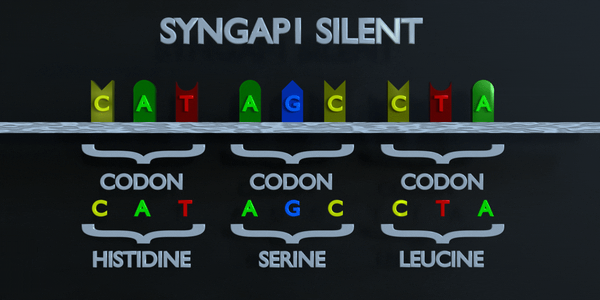
Silencieux
Dans une mutation silencieuse, un nucléotide est substitué mais le même acide aminé est produit de toute façon. Cela peut se produire car plusieurs codons peuvent coder pour le même acide aminé. Par exemple, TTA et CTA codent tous deux pour la leucine, donc si le premier T est remplacé par un C, le même acide aminé se formera et la protéine ne sera pas affectée.
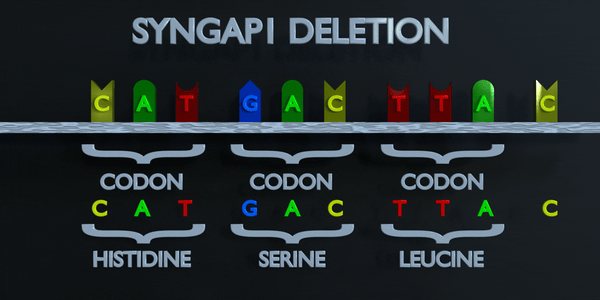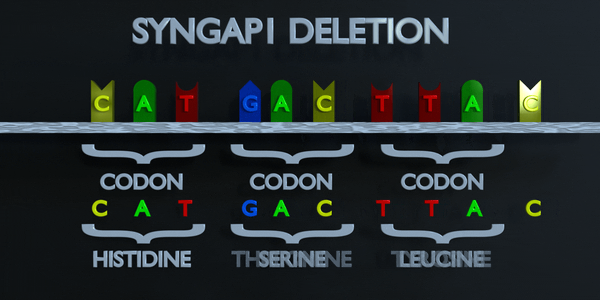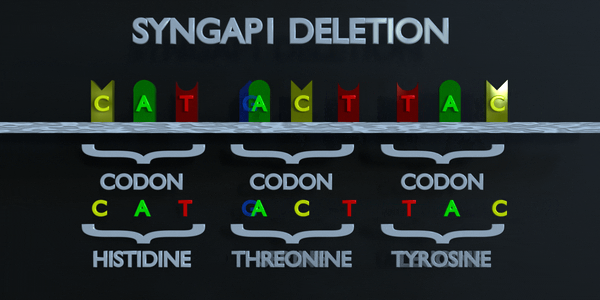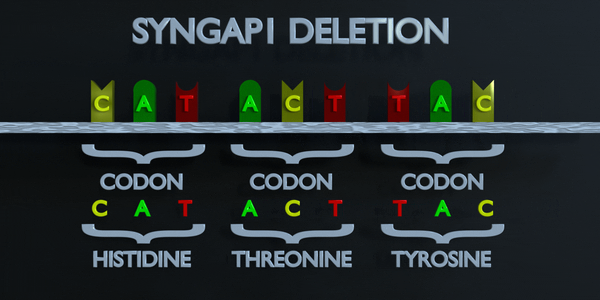
Effacement
Une mutation par délétion est une erreur dans le processus de réplication de l'ADN qui supprime les nucléotides du génome. Une mutation par délétion peut éliminer un seul nucléotide ou des séquences entières de nucléotides. L'effet de la mutation par délétion sera déterminé par l'endroit où elle se produit dans le gène et par le nombre de nucléotides supprimés. Le code génétique est lu en triplets par des enzymes productrices de protéines. Si trois nucléotides ou plus sont perdus dans un gène, des acides aminés entiers peuvent être absents de la protéine créée, ce qui peut avoir de graves effets fonctionnels. La perte d'un seul nucléotide n'est souvent pas meilleure, car une mutation par décalage de cadre peut se produire. Une mutation de décalage de cadre déplace le gène entier et modifie tous les codons triplets d'origine. Une mutation de ce type peut amener un gène à produire un gène complètement non fonctionnel.